

介绍
PyTorch是一个开源的机器学习库,广泛用于计算机视觉和自然语言处理等应用。PyTorch提供了丰富的模块,可以方便地构建和训练神经网络。
架构图
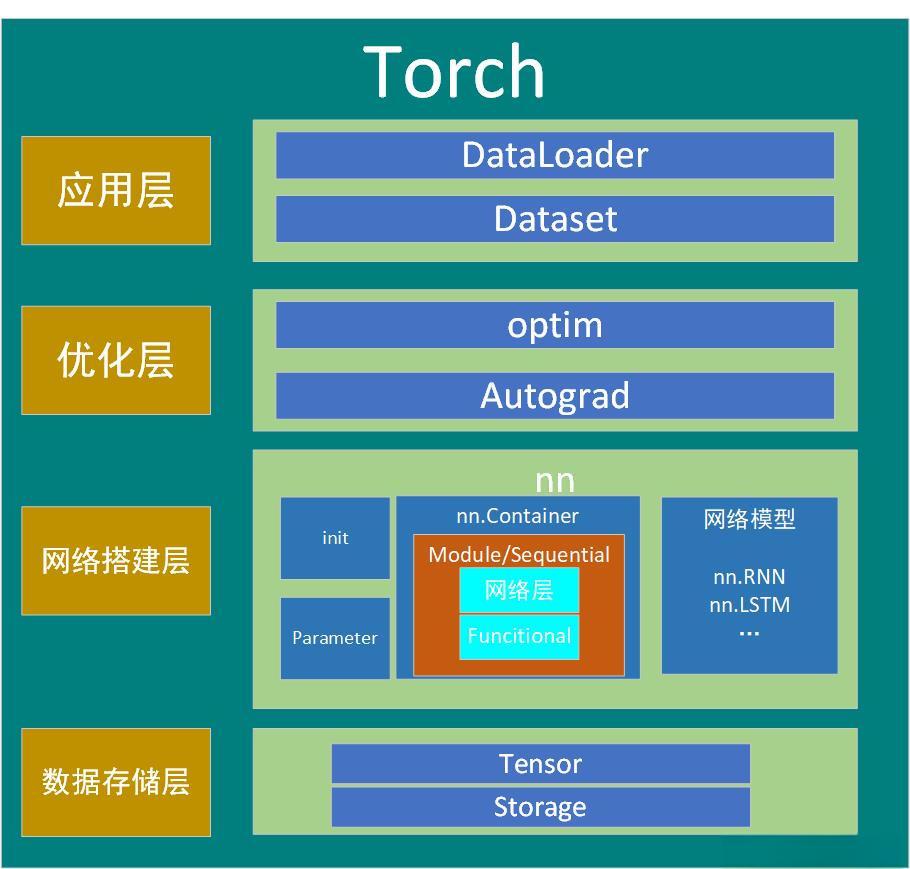
数据存储层:管理数据存储和内存分配,Tensor在整个计算图中流动并执行操作
Tensor: PyTorch中最基础的数据结构,类似于NumPy的数组,但支持GPU加速。Tensor可以存储各种类型的多维数组,并且可以在CPU和GPU之间快速转换。
Storage: 是Tensor底层的实现,用来管理实际存储的内存。Storage是低层次的,用于分配内存,而Tensor则是更高层的接口。
网络搭建层:负责网络的搭建,定义了神经网络的结构、层的堆叠方式以及初始化参数等
init: 用于初始化模型的参数,比如权重和偏置。可以自定义初始化策略,确保网络的训练效果。
Parameter: Parameter类是特殊的Tensor,当被赋予nn.Module时,它会自动被注册为可学习的参数(即在反向传播时被更新的权重)。
nn.Container: nn.Module的容器类,帮助组织网络中的多个层,比如nn.Sequential。
Module/Sequential: nn.Module是PyTorch中所有神经网络层的基类,可以被继承来创建自定义模型。nn.Sequential是容器类,用于按顺序将多个层组合起来。
Functional: torch.nn.functional提供了许多函数,比如激活函数、卷积操作等。相比于nn.Module中的层,functional提供了操作符的直接调用,而不需要保存状态。
网络模型: PyTorch提供了多种现成的网络模块,例如nn.RNN、nn.LSTM等。这些都是常见的神经网络模型,用户可以直接使用或者进行扩展。
优化层:负责计算梯度并进行参数更新,自动微分功能显著简化了深度学习的反向传播实现
optim: 这一模块包含了PyTorch中各种优化器(如SGD、Adam等),它们根据损失函数的梯度对模型参数进行更新,帮助模型逼近最优解。
Autograd: PyTorch的自动微分模块,能够自动计算所有操作的梯度。它通过动态计算图记录每次操作,允许模型在每次前向传播中动态构建和反向传播。
应用层:对数据的加载和处理,将数据转换为模型可以处理的格式,并通过批次传递给模型进行训练或测试
DataLoader: 负责批量加载数据,可以并行处理、打乱数据,并支持自定义的数据预处理和数据增强。
Dataset: 这个类表示数据集,用户可以继承并自定义__getitem__()和__len__()方法来加载特定格式的数据。
常用模块
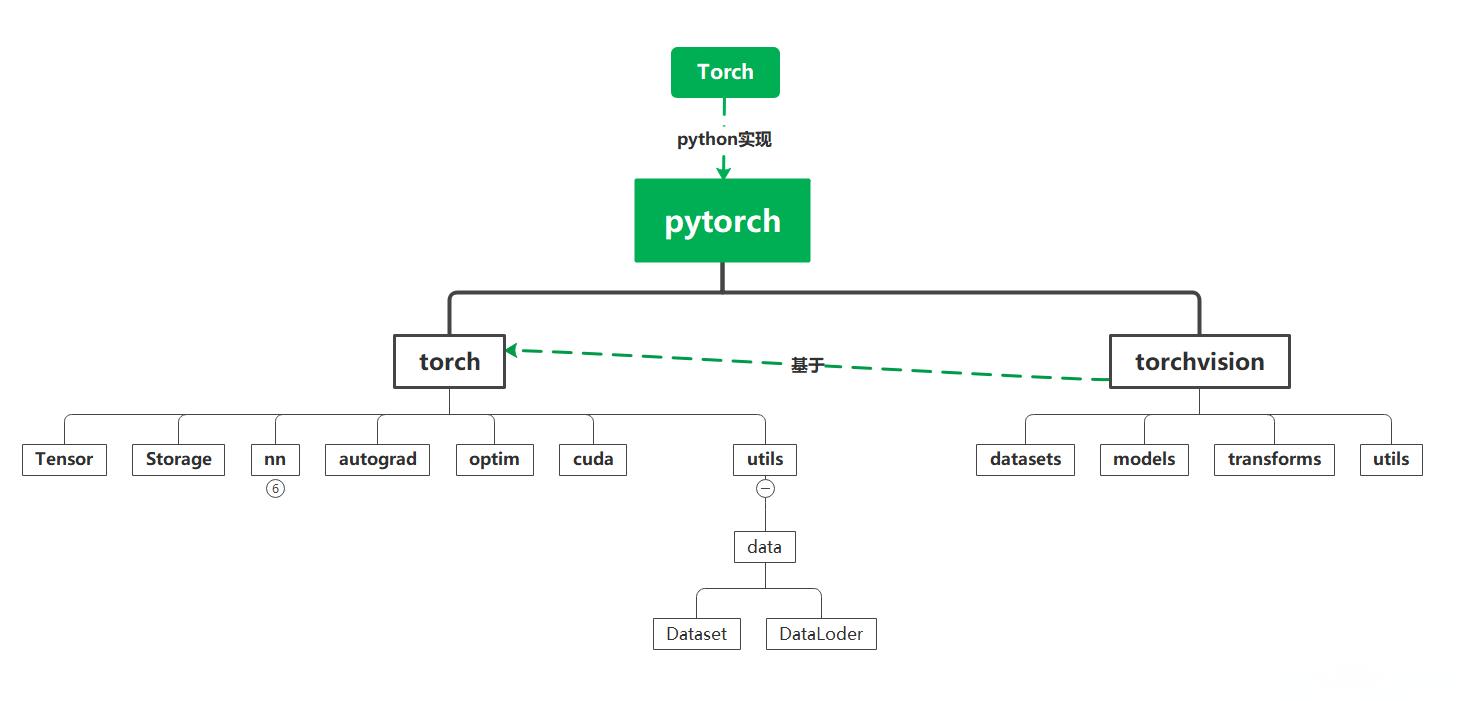
张量(Tensor)
张量是pytroch中最重要的数据类型,神经网络中操作的数据都是张量。输入的图片是一个张量,中间的隐藏层也是张量,最后输出的结果也是张量。
存储(Storage)
Storage是Tensor的底层实现,用来管理实际存储的内存。Storage是低层次的,用于分配内存,而Tensor则是更高层的接口。
自动求导系统(Autograd)
用于自动计算梯度,支持反向传播。
优化器(Optimizers)
用于更新模型参数,常见的优化器包括SGD、Adam等。
GPU
用于GPU加速的模块,定义了与CUDA运算相关的一系列函数
神经网络模块(nn)
所有神经网络模型的基类,提供构建神经网络所需的模型基类(Module)、各种层(Layers)、损失函数(Loss Functions)、激活函数(Activation Functions)。
模型基类(Module): 所有神经网络模型的基类。
各种层(Layers): 如全连接层(nn.Linear),卷积层(nn.Conv2d),池化层(nn.MaxPool2d)等。
损失函数(Loss Functions): 如交叉熵损失(nn.CrossEntropyLoss),均方误差损失(nn.MSELoss)等。
激活函数(Activation Functions): 如ReLU(nn.ReLU),Sigmoid(nn.Sigmoid)等。
工具集(torch.utils)
包含了高效的工具和类,简化了数据处理、训练流程、模型保存等任务
数据/数据集加载和处理(data/datasets):用于加载和预处理数据集,支持批处理和数据增强。
预训练模型(utils.model_zoo):预训练模型
可视化(utils.tensorboard):训练结果的可视化
其他模块
计算机视觉(torchvision)
用于计算机视觉任务,提供预训练模型和常用数据集。
torchtext自然语言处理
用于自然语言处理任务,提供文本处理工具。
torchaudio语音处理
用于音频处理任务。