
前言
目前AI火的一塌糊涂,开源AI模型也如雨后春笋般涌现出来。其中最大的社区就是Hugging Face。作为新手的我,看到Hugging Face的模型,感觉非常好用。但是下载大模型的时候,发现文件特别多,不知道如何选择。今天就来介绍一下Hugging Face下载大模型的相关文件说明。
Hugging Face
Hugging Face犹如AI界的Github,是一个开源的AI模型的开源社区和平台,致力于推动机器学习和人工智能的发展。它提供了丰富的预训练模型、数据集和工具,特别在自然语言处理(NLP)领域有着显著的影响。有包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。也包括国内很多知名企业的模型。
注:
由于一些原因,目前访问需要一些特殊条件。
可以通过镜像源进行下载。或者通过Model Scope 社区进行下载。
文件说明
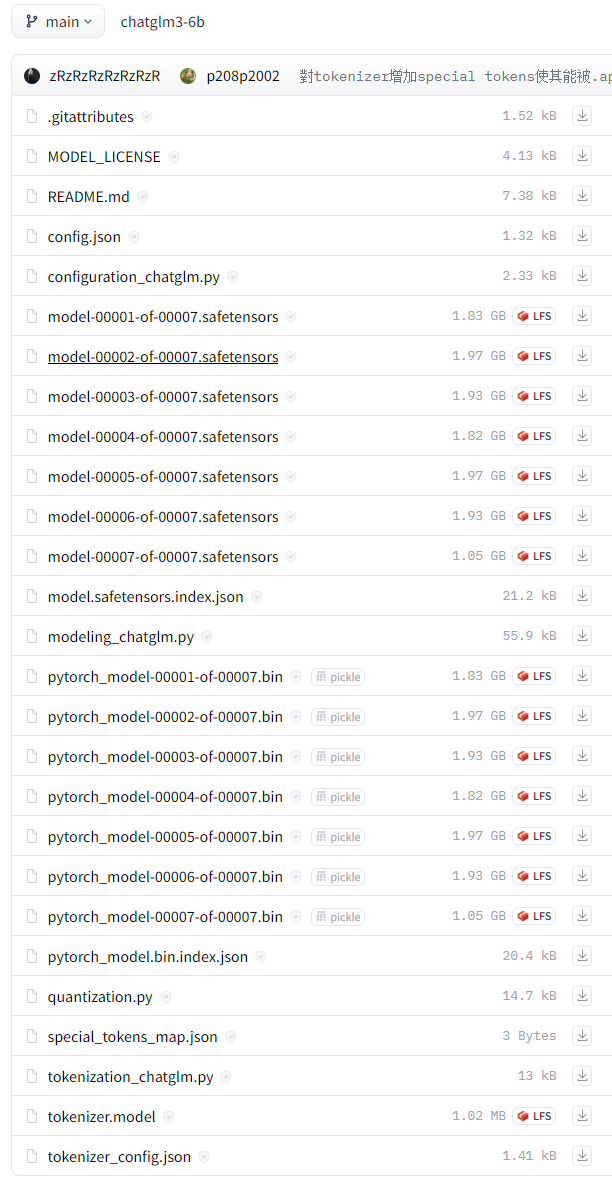
在Hugging Face的模型存储库中,这些文件通常用于表示预训练模型及其相关配置、模型权重、词汇表和分词器等。下面是这些文件的一般作用:
.gitignore :是一个纯文本文件,包含了项目中所有指定的文件和文件夹的列表,这些文件和文件夹是Git应该忽略和不追踪的
MODEL_LICENSE:模型商用许可文件
REDAME.md:用过GitHub的用户应该知道,这个文件是用于描述项目的主要内容。
config.json:模型配置文件,包含了模型的各种参数设置,例如层数、隐藏层大小、注意力头数及Transformers API的调用关系等,用于加载、配置和使用预训练模型。
configuration_chatglm.py:是该config.json文件的类表现形式,模型配置的Python类代码文件,定义了用于配置模型的 ChatGLMConfig 类。
modeling_chatglm.py:源码文件,ChatGLM对话模型的所有源码细节都在该文件中,定义了模型的结构和前向传播过程,例如 ChatGLMForConditionalGeneration 类。
model-XXXXX-of-XXXXX.safetensors:安全张量文件,保存了模型的权重信息。这个文件通常是 TensorFlow 模型的权重文件。
model.safetensors.index.json:模型权重索引文件,提供了 safetensors 文件的索引信息。
pytorch_model-XXXXX-of-XXXXX.bin:PyTorch模型权重文件,保存了模型的权重信息。这个文件通常是 PyTorch模型的权重文件。
pytorch_model.bin.index.json:PyTorch模型权重索引文件,提供了 bin 文件的索引信息。
注: 说明1:
在实际使用过程中不需要将这两种类型的权重文件都下载下来,只需要下载一类即可,还包括对应的.index.json;在使用过程中都是调用transformers包进行加载,两种格式都可以加载,即使在PyTorch环境中也可以下载.safetensors格式的模型权重进行加载,只要安装了transformers包即可。
说明2:
传统的,Pytorch会保存一个完整的文件,包含参数名到权重的映射关系。这个映射关系表称为state_dict。
在模型参数小于10亿时,上面代码一般运行没有问题。但是对于大模型(超过10亿参数),上面的代码就有点不能用了。像ChatGPT模型有1760亿个参数,就算使用全精度(bfloat16数据类型)来保存权重,它会消耗352GB的存储空间。对于超级计算机,可以完成加载、训练和保存的任务,但是对于用户侧的推理,这个存储需求就要另外想办法了。
这个方法就是将模型权重文件切分为多个文件,如果模型.bin文件形式进行保存,会得到两种后缀格式的文件:
pytorch_model_xxxxx-of-000XX.bin:每个都是模型权重的一部分,通过这种文件格式切分,可以在内存中一个一个加载(不用全部加载,导致超出内存存储能力。可以实现加载部分权重到模型、移动到GPU或其他设备上进行计算、以及加载下一部分权重时,去除上一部分已加载的权重来释放内存或显存等)。与加载全部的模型不同,我们的机器只需要能够加载最大的一个checkpoint即可,这里称为分片。
pytorch_model.bin.index.json:参数名 与 模型bin文件的映射表。
quantization.py:量化代码文件,包含了模型量化的相关代码。
special_tokens_map.json:特殊标记映射文件,用于指定特殊标记(如起始标记、终止标记等)的映射关系。
tokenization_chatglm.py:分词器的Python类代码文件,用于chatglm3-6b模型的分词器,它是加载和使用模型的必要部分,定义了用于分词的 ChatGLMTokenizer 类。
tokenizer.model:包含了训练好的分词模型,保存了分词器的模型信息,用于将输入文本转换为标记序列;通常是二进制文件,使用pickle或其他序列化工具进行存储和读取。
tokenizer_config.json:含了分词模型的配置信息,用于指定分词模型的超参数和其他相关信息,例如分词器的类型、词汇表大小、最大序列长度、特殊标记等
LFS:Large File Storage,大文件存储,这样的文件都很大,如果使用git需要安装LFS
brew install git-lfsGGUF:上图没有,大模型文件存储格式新宠GGUF,采用相应的工具将原始模型预训练结果转换成GGUF之后可以更加高效的使用。